
Big data analytics going 100x faster with Hive and Stinger
![]()
Apache implemented Hive as data warehouse platform for analysis of data using SQL, on the top of Hadoop map-reduce framework for data mining and data preparation use cases. These usage patterns remain very important but with widespread adoption of Hadoop, the enterprise requirement for Hadoop to become more real time or interactive has increased its importance as well.
What is Hive?
Hive, originally developed by Facebook and later owned by Apache, is a data storage system that was developed with a purpose to analyze organized data. Working under an open-source data platform called Hadoop, Apache Hive is an application system that was released in the year 2010 (October).
Introduced to facilitate fault-tolerant analysis of hefty data on a regular basis, Hive has been used in big data analytics and has been popular in the realm for more than a decade now.
Even though it has many competitors like Impala, Apache Hive stands apart from the rest of the systems due to its fault-tolerant nature in the process of data analysis and interpretation.
Understanding Hive in Big Data
Apache Hive is a particularly efficient tool when it comes to big data (exponential data that is to be analyzed). A warehouse data software that supports the data analysis process of big data on a regular basis, the concept of hive big data is quite popular in the technological realm.
As data is stored in the Apache Hadoop Distributed File System (HDFS) wherein data is organized and structured, Apache Hive helps in processing this data and analyzing it producing data-driven patterns and trends. Fit to be used by organizations or institutions, Apache Hive is extremely helpful in big data and its ever-changing growth.
The concept of Structured Query Language or SQL software is involved in the process which communicates with numerous databases and collects the required data. Understanding Hive big data through the lens of data analytics can help us get more insights into the working of Apache Hive.
By using a batch processing sequence, Hive generates data analytics in a much easier and organized form that also requires less time as compared to traditional tools. HiveQL is a language similar to SQL that interacts with the Hive database across various organizations and analyses necessary data in a structured format.
What is Hive in Hadoop?
No one can better explain what Hive in Hadoop is than the creators of Hive themselves: “The Apache Hive™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. The structure can be projected onto data already in storage.”
In other words, Hive is an open-source system that processes structured data in Hadoop, residing on top of the latter for summarizing Big Data, as well as facilitating analysis and queries.
Now that we have looked into what is Hive in Hadoop, let us take a look at the features and characteristics.
Hive’s Features
The following are Hive’s chief characteristics to keep in mind when using it for data processing:
• Hive is designed for querying and managing only structured data stored in tables
• Hive is scalable, fast, and uses familiar concepts
• Schema gets stored in a database, while processed data goes into a Hadoop Distributed File System (HDFS)
• Tables and databases get created first; then data gets loaded into the proper tables
• Hive supports four file formats: ORC, SEQUENCEFILE, RCFILE (Record Columnar File), and TEXTFILE
• Hive uses an SQL-inspired language, sparing the user from dealing with the complexity of MapReduce programming. It makes learning more accessible by utilizing familiar concepts found in relational databases, such as columns, tables, rows, and schema, etc.
• The most significant difference between the Hive Query Language (HQL) and SQL is that Hive executes queries on Hadoop’s infrastructure instead of on a traditional database
• Since Hadoop’s programming works on flat files, Hive uses directory structures to “partition” data, improving performance on specific queries
• Hive supports partition and buckets for fast and simple data retrieval
• Hive supports custom user-defined functions (UDF) for tasks like data cleansing and filtering. Hive UDFs can be defined according to programmers’ requirements
Hence, Hortonworks came up with Apache Stinger Initiative which enables hive to answer queries within 5-30 seconds. This includes queries like big data exploration, visualization, and parameterized reports.
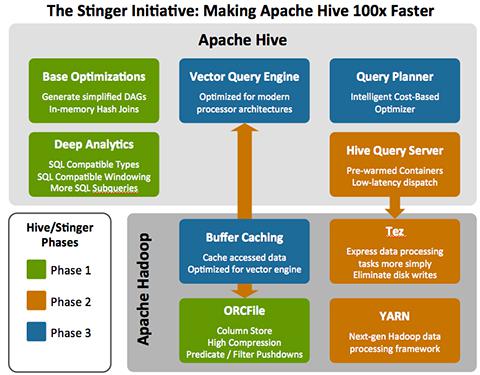
The Stinger Initiative is a collection of development threads in the Hive community that will deliver 100 times performance improvements with SQL compatibility. It is a live project with THREE defined phases to be delivered over the next few months all in the open community (Phase1 results have already demonstrated an initial 45x improvement). Following architecture provides the overview:
 Base Optimizations
Base Optimizations
Stringer worked on optimization and enabled the optimizer to automatically pick the map join. It also introduced in-memory hash join that reads the small table into a hash table and scans through the big file to generate output.
Deep Analytics
With Stinger, Hive is more suitable to deliver the decision support queries people want to perform in Hadoop. This includes:
- SQL Compliance
- Support window/analytical functions (OVER clause)
– Multiple PARTITION BY and ORDER BY supported
– Windowing supported (ROWS PRECEDING/FOLLOWING)
– Aggregates Functions (RANK, FIRST_VALUE, LAST_VALUE, LEAD / LAG)
- Data Types:
– Add fixed point NUMERIC and DECIMAL type and size ranges from 1 to 53 for FLOAT
– Add VARCHAR and CHAR types with limited field size
– Added synonyms for compatibility (BLOB for BINARY, TEXT for STRING, REAL for FLOAT etc.)
- SQL Semantics:
– Sub-queries in IN, NOT IN, HAVING.
– EXISTS and NOT EXISTS
Vector Query Engine
Stinger outlines a new architecture for the Hive query execution engine. It removes process buffers and allows Hive to speed records processed per second.
Query Planner
Generates more intelligent DAGs (Directed Acyclic Graph) based on properties of data being queried, e.g. table size, statistics, histograms, etc.
Buffer Caching
Generally, metadata and small dimension tables are frequently used in queries. Service built into YARN or TEZ buffer frequently used data into memory so it is not always read from disk.
TEZ
Tez eliminates Hive’s latency and throughput constraints that results from its reliance on MapReduce. Tez optimizes Hive job execution by eliminating unnecessary tasks, synchronization barriers, and reads from and write to HDFS. This optimizes the execution chain within Hadoop and drastically speeds up Hive’s workload processing. It does not write intermediate output to HDFS and hence lightens disk and network usage. It also enables the pipelining of jobs.
ORC File
Apache introduces a new columnar file format (i.e. ORCFile) within the Hive community to provide a more modern, efficient, and high performing way to store Hive data. Benefits of ORC Files
- Tightly aligned to Hive data model
- Decompose complex row types into primitive fields for better compression and projection
- Only read bytes from HDFS for the required columns.
- Store column level aggregates in the files.
With every passing day, the new discoveries around big data analytics is getting better, and in the times to come we are going to see the hype on big data finally reach its Peak of Inflated Expectations on the Gartner’s Hype cycle. But soon enough, enlightenment and productivity phase will follow. Big Data Analytics is the future with the vast amount of data that is being generated at a rapid pace. And its time when organizations start preparing ahead of time, start preparing to use their own big data by custom dashboard designs.
Originally published Dec 5, 2013 at 06:47, updated on February 18, 2022 for relevance and comprehensiveness.